IDs and References
The purpose of this design is to describe how we will compute Resource IDs during the FHIR ingestion process.
Background
To reduce the complexity of data consumption, we have agreed to persist resources with Literal References. Resources will be identified and addressed by their URL.
The data we ingest uses Logical References. For example, referencing a Organisation using the ODS Code. The referenced resource may not exist within the ingested bundle. Without computing a deterministic ID it would be required to perform multiple lookups on the FHIR server during ingestion.
Terminology
- Source Organisation - The organisation that is sending the data to ingest.
- Source Domain - The business domain where the source data originates from.
- Mapping Config - Configuration that defines what Mapping Template to use for a given input.
- Mapping Template - A Liquid template that defines how
$convertto FHIR.
Ingestion Overview
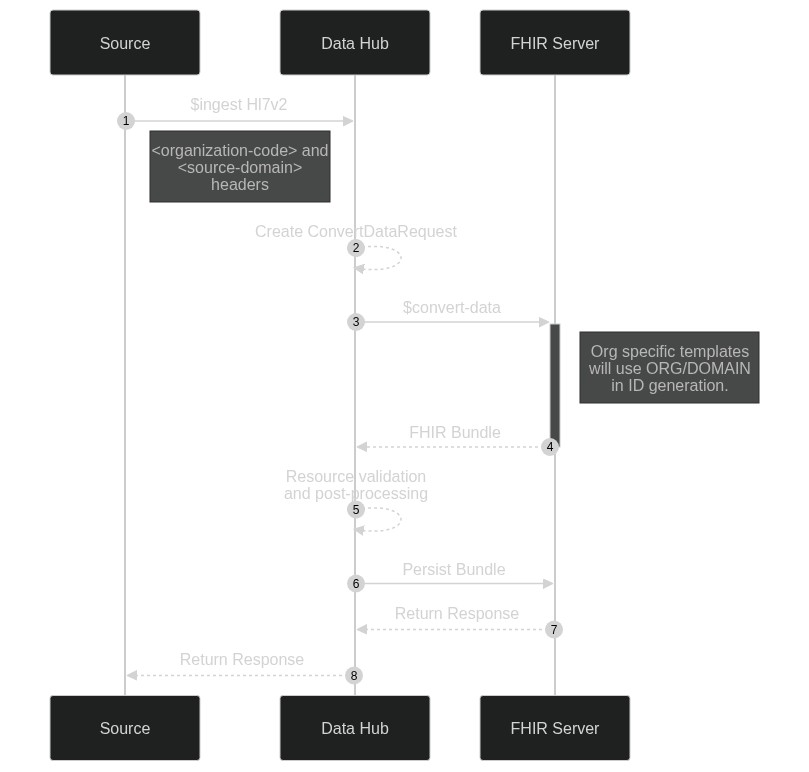
Process Steps
Step 1 $ingest request
Source data is sent to the Hl7v2 $ingest endpoint. The following inputs are captured in the HTTP request headers:
organisation-codesource-domaindata-type
Together, organisation-code and source-domain are used later to scope the ID generation.
Step 2 Create ConvertDataRequest
Data Hub will create a ConvertDataRequest which encapsulates the necessary information for conversion:
Input- from request bodyTemplateInfoOrganisationCode: from request headerDomain: from request headerDataType: from request headerResourceType
Step 3/4 $convert-data to FHIR
Data Hub will send the ConvertDataRequest to the $convert-data endpoint, which returns a FHIR bundle based on the required Liquid template.
The mapping process is responsible for generating the ID and Literal References for all resources.
Resource ID Generation
- Extract identifiers from the input segment or field;
- Combine the identifiers with resource type and base ID (optional) as hash seed;
- Compute hash as output ID
This is an example ID template for a Organization:
{{ OdsCode | generate_id_input: 'Organization', false | generate_uuid }}
This template would be used when mapping a new Organization:
{
"resourceType": "Bundle",
"type": "transaction",
"entry": [
{% for item in msg.orgs %}
{% evaluate orgId using 'ID/Organization' OdsCode: item.OdsCode -%}
{
"resource": {
"resourceType": "Organization",
"id": "{{ orgId }}",
The same template would be used to reference a Organization:
{% evaluate orgId using 'ID/Organization' OdsCode: ... -%}
{% assign fullOrgId = orgId | prepend: 'Organization/' -%}
{% include 'Reference/Organization' ID: encounterId, REF: fullOrgId -%}
Note: The complexity of ID generation is encapsulated in the
Id/Organizationtemplate. For consistency, this should be referenced from all top-level templates.
Base ID
The generate_id_input filter includes a concept of "base resource/base ID". Base resources are independent entities, like Patient, Organization, Device, etc, whose IDs are defined as base ID. Base IDs could be used to generate IDs for other resources that relate to them. It helps enrich the input for hash and thus reduce ID collision. For example, a Patient ID is used as part of hash input for an AllergyIntolerance ID, as this resource is closely related with a specific patient.
Scoped ID
For many resource types, it will be required to scope their ID on the Source Organisation and/or Source Domain. In this scenario, these values can be hard-coded in the top-level template.
This is an example ID template for a scoped Organization:
{% capture identifiers -%}
{{ SourceOrg }}_{{ SourceDomain }}_{{ OdsCode }}
{% endcapture -%}
{{ identifiers | generate_id_input: 'Patient', false | generate_uuid }}
This would be used when mapping a new scoped Organization:
{
"resourceType": "Bundle",
"type": "transaction",
"entry": [
{% for item in msg.orgs %}
{% evaluate orgId using 'ID/Organization' OdsCode: item.OdsCode, SourceOrg: 'NHS', SourceDomain: 'ODS' -%}
{
"resource": {
"resourceType": "Organization",
"id": "{{ orgId }}",
Because the ID is now scoped, the same inputs are required when referencing a Organization from a top-level template:
{% evaluate orgId using 'ID/Organization' OdsCode: ..., SourceOrg: 'NHS', SourceDomain: 'ODS' -%}
{% assign fullOrgId = orgId | prepend: 'Organization/' -%}
{% include 'Reference/Encounter/Subject' ID: encounterId, REF: fullOrgId -%}
It is possible for the SourceOrg and SourceDomain to be different from the ingest request. For example:
- A01 from 'InPatient' Domain
- Encounter '0123' from Domain1: "UCH_InPatient_0123"
- A03 from 'ED' Domain
- Condition from 'ED' references Encounter from 'InPatient'. By default, our lookup would be incorrect: "UCH_ED_0123"
Step 5 Resource validation and post-processing
See here.
Step 6 Persist Bundle
In order to preserve the generated Resource IDs, the bundles are created with PUT requests, instead of POST requests. This bundle is sent to the FHIR Server for processing.
Exception for Patient
The Patient resource is considered a local cache of PDS. In PDS, the NHS Number is used as the resource ID. To remain consistent with the upstream data source, we will also use the NHS Number in the FHIR Server.
As a result:
- Liquid mapping will reference
Patientusing the NHS Number: "Patient/{NhsNumber}" - No post processing is required. If the
Patientdoes not exist, it will be retrieved and persisted on read. - The
PatientModulehandlesGET /Patient/<NhsNumber>using the existingSearchStrategylogic (read locally, and if required read upstream and persist). Patientwill be persisted as-is from PDS.
It is possible other resources may need to follow a similar pattern - typically when the referenced resource is owned by a national system. For example, E-Referral Service, or E-Prescribing Service.
Limitations of design
This design does include some limitations we should be aware of:
- Using a generated literal ID to reference a resource lacks a referential integrity check. For example, while the generated ID would be valid, the
Encounterwe are referencing may not exist. By design, the FHIR Server does not enforce referential integrity among FHIR resources. - This is by-design for
Patient. For this resource, we will persist-on-read. - For other resources, we could iterate the bundle post-mapping and validate the references have integrity. This would require a number of requests to
GET /{ResourceType}/{Id}. - Mapping has no control over the referenced resource. Therefore, we are unable to update the bi-directional reference. For example, we could map a literal reference from a
Conditionto anEncounter. However, unless theEncounteris also in the bundle, we are unable to update theEncounterto also reference theCondition. - A potential mitigation would be to iterate the bundle post-mapping and ascertain which referenced resources would also require updating. These could be appended to the bundle. This is considered non-trivial, and would likely require mapping configuration.